
A TKK megalakulása óta számos önálló és konzorciumos projektet valósított meg a központvezető, Bartha Csilla irányításával.
Többnyelvűség Európában; Nyelv- és oktatáspolitika:
Az Európai Bizottság által társfinanszírozott Language Rich Europe (LLP/DG EAC/41/09, 2010–2013) projektum munkálatai középpontjában az európai többnyelvűséget támogató nyelv- és oktatáspolitikai jó gyakorlatok kidolgozása állt.
2012–2015 között eredményesen valósult meg a Language and Education Addressed through Research and Networking by Mercator/LEARNMe c. kutatás (530895-LLP-1-2012-1-NL-KA2-KA2NW). A kutatás a nyelvi diverzitás kérdéskörét járta körbe a nyelvpolitika, az oktatás és a média területein.
A nyelvi variáció szociokulturális aspektusai az észt és a magyar nyelvterületen c. kutatás az Észt Akadémia, a TKK és az ELTE BTK közötti együttműködés eredménye. Célja a nyelvhasználat és a volt szocialista országokban jelentkező identitáskonstrukciók vizsgálata, a hasonló nyelvi-társadalmi kihívások közös megoldási lehetőségeinek megtalálása.
Hazai és határon túli kisebbségek közösségek nyelvhasználata, identitása:
A magyarországi román területi nyelvváltozatok szótára/Dictionary of Regional Romanian Spoken in Hungary/Dicţionarul graiurilor româneşti din Ungaria – DGRU (2018–2021) c. Nemzetközi MTA Mobilitás pályázatban (PROJEKT 2017-55, NKM – 115/2018, 37/2019, 8/2020) a partnerintézetek és részt vevő kutatók a Nyelvtudományi Intézet: Borbély Anna (projektvezető) és Institute of Linguistics of the Romanian Academy „Iorgu Iordan – Alexandru Rosetti”/Institutul de Lingvistică al Academiei Române “Iorgu Iordan – Alexandru Rosetti”: Maria Marin, Iulia Mărgărit, Daniela Răuţu, Carmen-Ioana Radu és Marinela Bota. A DGRU sokrétű nyelvi források (nyelvészeti atlaszok, különböző folklórkiadványok, nyelvjárási szöveggyűjtemények, szociolingvisztikai és nyelvjárási terepmunkák során gyűjtött hangfelvételek stb.) alapján készül számos tudományterület (a lexikográfia és a lexikológia, a román nyelvtörténet, a szociolingvisztika, a néprajz stb.) szakembereinek, valamint a kutatott területek nyelvének, szokásainak és hagyományainak ismerete iránt érdeklődőknek. Fontos oktatási segédanyagként szolgálhat továbbá a Népismeret című nemzetiségi tantárgyhoz is. A készülő DGRU egybegyűjti a magyarországi települések román népességére jellemző szókészletet, azokét, ahol a román nyelvet kommunikációs eszközként már nem használják (Bedő/Bedeu, Körösszegapáti/Apateu, Körösszakál/Săcal), és azokét is, ahol a népesség egy rész vagy egésze még használja (Battonya/Bătania, Elek/Aletea, Gyula/Giula, Kétegyháza/Chitighaz, Magyarcsanád/Cenadul-Unguresc, Méhkerék/Micherechi, Pusztaottlaka/Otlaca-Pustă). A szigorú betűrendben feldolgozott címszavak szócikkeinek szerkezeti felépítése három fő részre oszlik: 1. címszó, nyelvtani kategóriák (szófaja, alaki felépítése), területi adatok használatáról, a címszó rövid definíciója, illusztratív idézetek, szinonimák; 2. fonetikai és/vagy morfológiai változatok; 3. etimológia. Az MTA Mobilitás pályázat részfeladatai: a módszertan kidolgozása, az elvek és a szabályok meghatározása a nyelvi anyag kiválasztásáról és bemutatásáról; a jelenleg rendelkezésre álló források összesítése; újabb adatgyűjtés, terepmunka; publikált forrásokból és hangfelvételekből származó adatgyűjtés, listázás; a címszavak meghatározása és betűrendbe szedése; a szócikkek megírása, változatok, helységek és források megnevezése, definíciók, reprezentatív idézetek stb. kiválasztása; a szinonimák listájának elkészítése; etimológiák. A pályázat során megvalósult terepmunkák (Pusztaottlaka, Lökösháza, Elek 2018; Méhkerék 2019) és tudományos műhelybeszélgetések (Román Akadémia, Bukarest 2018, 2019; Nyelvtudományi Intézet 2019; Online 2020). A munkálatok folytatásában elkészül egy papíralapú szótár, a továbbiakban majd ennek digitális-internetes hozzáférését is tervezzük. A DGRU projekt román/angol nyelvű linkje a partnerintézet honlapján itt olvasható:
http://www.lingv.ro/index.php?option=com_content&view=article&id=419&Itemid=282
A nyelvi másság dimenziói: A kisebbségi nyelvek megőrzésének lehetőségei (NKFP 5/126/2001, ELTE BTK – MTA NYTI 2001–2004) és a Dimensions of Linguistic Otherness (European Commission, FP6, Priority 7, Specific Support Action, 2006–2008) c. projektek hat magyarországi kisebbségi közösség nyelvhasználatát és nyelvi attitűdjeit térképezték fel. E kutatások és a magyarországi románok körében folytatott szociolingvisztikai kutatás eredményeinek szintéziseként kidolgozásra került a „fenntartható kétnyelvűségi modell” is (l. Borbély Anna 2014).
A TKK munkatársainak egyéni kutatási területei kiterjednek a kisebbségi közösségek, köztük a cigány nyelvek és közösségek vizsgálatára is. Zajlik a határon túli magyar nyelvhasználat és oktatás aspektusait vagy a magyarországi németek nyelvcsere-folyamatait vizsgáló kutatás is. Az elmúlt években kutatások zajlottak a cigány (romani) nyelv megjelenéséről a digitális közösségi térben, internetes diskurzusokban, a sztenderdizációval, nyelvhasználattal, diskurzusmintákkal, identitással összefüggő kérdésekre fókuszálva. Kutatások folytak a cigány-magyar kétnyelvűség és az iskolai oktatás kapcsolatáról. Egyedülálló korpusz született a Hodász községben a cerhari-magyar kétnyelvű közösség empirikus vizsgálata során is.
Jelnyelvi kutatások:
JelEsély: A magyar jelnyelv sztenderdizációjának elméleti és gyakorlati lépései (TÁMOP 5.4.6/B-13/1-2013-0001)
A Kutatóközpontban zajló jelnyelvi kutatások több nagyobb projekt munkálatai mentén, valamint további jelnyelvi grammatikai és szociolingvisztikai vizsgálatokhoz és egyéni vizsgálatokhoz s a projekteket támogató doktori kutatásokhoz kapcsolódva valósulnak meg.
Kiemelkedő és az EFOP-projektum fontos előzményét is jelentő kutatás a 2013 és 2015 között végzett JelEsély: A magyar jelnyelv sztenderdizációjának elméleti és gyakorlati lépései (TÁMOP 5.4.6/B-13/1-2013-0001) c. projekt. A kutatás a magyar jelnyelv első, hiánypótló, tudományos megalapozottságú szociolingvisztikai és grammatikai leírását hozta létre. A projektben a szociolingvisztika, a pszicho- és neurolingvisztika, az elméleti nyelvészet, a jelnyelvészet és a nyelvtechnológia szakértői, valamint a gyógypedagógia, a jog és az informatika szakemberei mellett – jelentős számban – számos érintett, siket munkatárs végezte a munkálatokat. Bővebben…

Akadálymentesített infokommunikációs szolgáltató platform fejlesztése, hallás- és látássérült személyek számára (EFOP-1.1.5-17-2017-00006)
2018 januárjában indult el és 2019 decemberében zárult le a Nyelvtudományi Intézet, a Siketek és Nagyothallók Országos Szövetsége, valamint a Magyar Vakok és Gyengénlátók Országos Szövetségének konzorciumában megvalósuló Akadálymentesített infokommunikációs szolgáltató platform fejlesztése, hallás- és látássérült személyek számára (EFOP-1.1.5-17-2017-00006) című nagyszabású projekt. A Nyelvtudományi Intézet Többnyelvűségi Kutatóközpontja a projektben a megalapozó háttérkutatások mellett célzott szótárkutatási, szótárfejlesztési és szókészlet-bővítési feladatokat látott el, a munkálatok célja egy, elsősorban a siketeket, valamint a tolmácsokat különböző témákban és helyzetekben segítő, tudományosan megalapozott digitális jelnyelvi szótár adatbázisának létrehozása. 2018-ban megtörtént a hozzáférhető magyar jelnyelvi szótárak, jelgyűjtemények feltérképezése, a nemzetközi jelnyelvi szótárak felgyűjtése és több szempontú metaelemzése, továbbá a hazai jelnyelvi anyagok fogalomkészletének, tematikai felépítésének szisztematikus vizsgálata. A technológiai és személyi háttér felállítását követően ugyancsak elindultak a stúdiófelvételek és folyamatos tesztelések, valamint összeálltak a szótárhoz kapcsolódó ellenőrzési és annotációs irányelvek is.
A projekt során különösen nagy gondot fordítottunk a terminológiai kutatásokra is. A terminológiai kérdések, fejlesztések ugyanis korunkban, a felgyorsult technikai fejlődés, a globalizáció és a virtuális kommunikáció jelenségei miatt minden nyelv kapcsán kiemelten fontossá válnak, a magyar jelnyelv szempontjából pedig különösen lényegesnek tekinthetők. A magyar jelnyelv esetében – fejlődéstörténetéből, vizuális jellegéből, használói közösségének sokáig marginalizált társadalmi helyzetéből adódóan – nem zajlott le az írásbeliséggel rendelkező nemzeti nyelvek történetében dokumentálható sztenderdizáció folyamata. Ebből adódóan a terminushasználat kérdései közvetlenül és egy sztenderdizált nyelvnél súlyosabban összefüggnek a funkcionális célú konszenzusok kialakításának igényével, legfőképpen az oktatás területén (annak minden, a szociolingvisztikai kutatásokból jól ismert következményeivel és esetleges veszélyeivel együtt), ezért minden ilyen irányú fejlesztés vagy döntés – legyen az tudatos vagy tudattalan, átgondolt vagy megalapozatlan – jelentős következményeket vonhat maga után a jelnyelvhasználó közösség egészére nézve.
A jelnyelvi terminológiai kérdések tehát megkerülhetetlenek bármely jelnyelvi szótár építése során, és komoly elméleti és módszertani kérdéseket vetnek fel, amelyekre a válaszadás kiterjedt és összetett tudományos munkát igényel (pl. elméleti reflektálás, módszertani és kutatásetikai alapelvek kidolgozása és implementálása, módszertani megoldások tervezése stb.)
Ezek mellett a terminológiai kérdéskör jelentősége különösen nagy a jelnyelv oktatásbeli használata, oktatási szerepének növekedése miatt. Bár jelnyelven is mód van minden tudományos jelenség és tartalom kifejezésére, egyelőre nincs egységes, native jelnyelvhasználók különböző körei által konszenzusosan elfogadott jelkincs és jel-terminológia az egyes tudásterületek (tananyagok) jelnyelvi oktatására, feldolgozására. Az egységes oktatási és szakszókincs ugyanakkor szükséges mind a hangzó nyelvi tananyaggal való teljes átjárhatóság megteremtéséhez, mind az önálló tudományos jelnyelvhasználat és jelnyelvi szakmai diskurzusok kialakulásához.
A jelnyelvi szakterminusok a különféle területeken dolgozó siket felnőttek és a tolmácsok számára is lényegesek, mind a mindennapi munkavégzés kapcsán, mind pedig a mindennapi ügyintézésben.
E nagyszabású, hosszú és összetett feladatot a siket közösség nélkül a NYTI TKK természetesen nem tudja elvégezni és nem is végezheti el. Ebben a folyamatban tudományos partnerként, szakmai támogatás és útmutatás kínálásával tudtunk és tudunk közreműködni. Ezen belül a téma különböző irányú (pl. szociolingvisztikai, terminológiai, oktatásmódszertani) tudományos kutatásainak, eredményeinek, fő meglátásainak átfogó, kritikai és integratív feldolgozásával meg tudja teremteni a tudományos alapot és felkínálni egy orientáló szakmai hátteret, iránymutatásokat a jelnyelvi terminológiai fejlesztések folyamatának – és egyes részlépéseinek – számára.
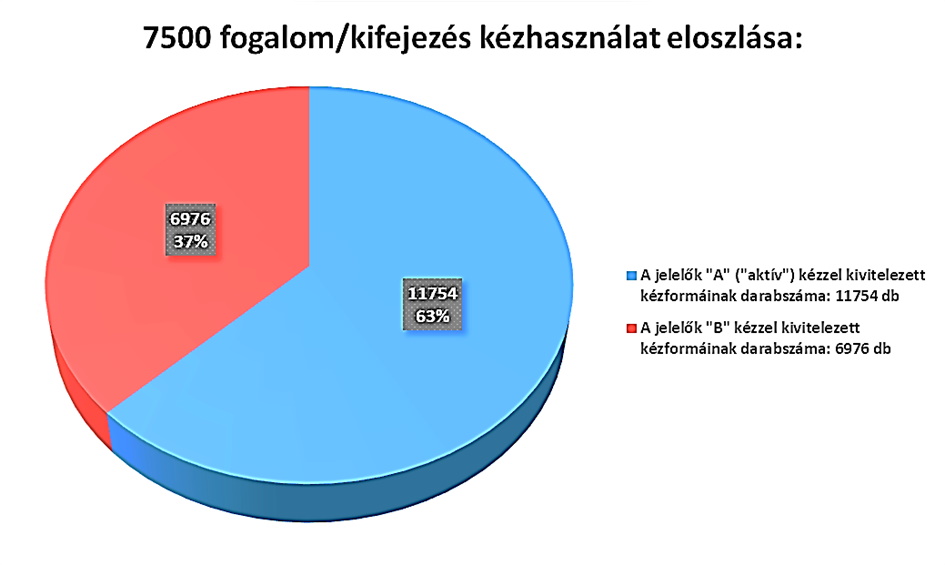
A fent ismertetett munkálatok eredményeként jött létre a konszenzusos, 7500 elemet tartalmazó szótár.
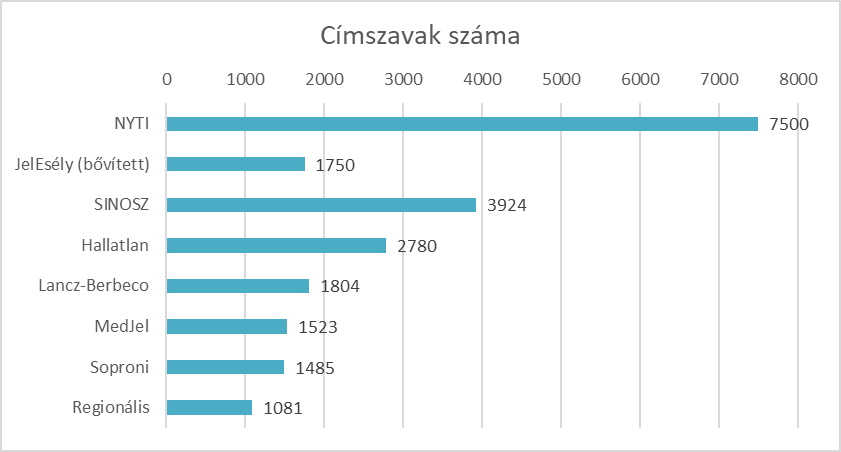
A szótárépítés során egy szótári elemhez kapcsolódva számos különféle jelzet, annotáció, metaadat stb. adható meg, ezért a Kontakt szótár fogalmi anyagát is elláttuk ilyenekkel (kategória-annotáció további alkategóriákkal, kézforma-annotáció, KER stb.)
A KER ajánlásai a kommunikációs igények és a lehetséges kontextusok alapján tematikai súlypontokat is kijelölnek. Ezek alapján a különböző nyelvek nyelvvizsgái és nyelvvizsga-központjai ajánlásaiban és/vagy segédanyagaiban – szintén bizonyos eltérésekkel – hasonló témakörök jelennek meg. Mivel az emberi kommunikáció fő feladatai és helyzetei alapvetően hasonló jellegűek – hiszen az emberi megismerés, a magánélet és a társadalmi élet fő jelenségei a legtöbb nyelvhasználó közösség esetében alapvetően hasonlóan szerveződnek –, az egyes nyelvek nyelvvizsgáihoz kapcsolható témakörök témái is hasonlóan épülnek fel, miközben egyes nyelvvizsgák leírásai részletesebb, mások átfogóbb csoportokat tartalmaznak. Ugyanakkor egyes nyelvek és nyelvhasználói közösségek nyelv- és kultúrspecifikus vonásaira is tekintettel kell lenni az ilyen témakör-leírásnál. Metaelemzések eredményeként 2820 elem elsődleges KER-besorolása már elkészült, ugyanakkor az összes item megfelelően megalapozott besorolásához, szintezéséhez egy bonyolult, sok szereplőt bevonó tesztelő folyamatra is szükség van, melynek során építeni szükséges a Pro-Sign munkálatok elveire és eredményeire.
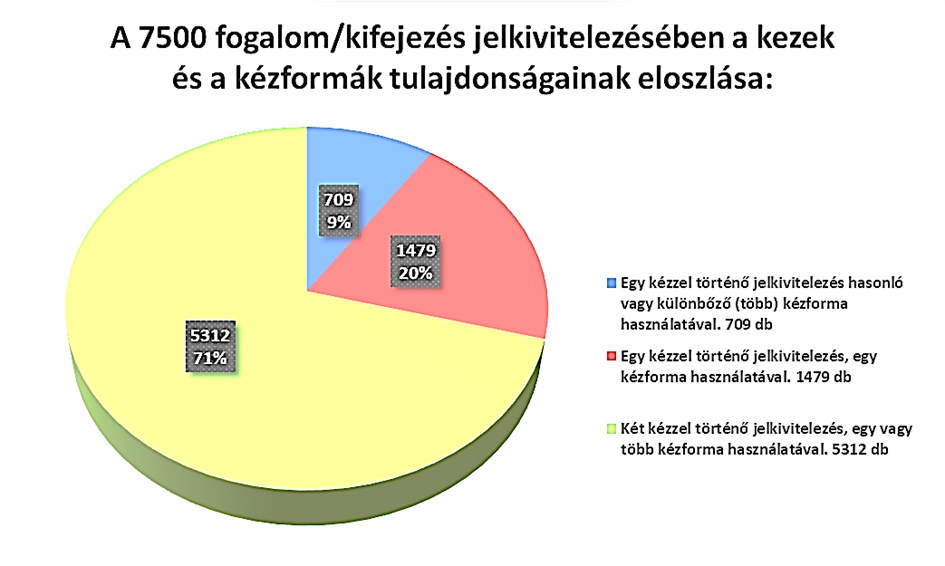
A jelkivitelezést illetően a 7500 item kiemelkedően magas része, 5312 item került kétkezesen kivitelezésre, 1479 egykezesen, egyetlen kézformával, míg 709 elem egykezesen, de több kézformával. A domináns kézen összesen 11754 kézformát, míg a nem domináns kézen 6976 kézformát annotáltunk.
Szótárfejlesztési munkálatainkba beépítettük az elmúlt évek szótári, grammatikai, illetve terminológiai kutatásainak tapasztalatait is, integrálva az ezek során gyűjtött és elemzett különböző szakkifejezéseket is (pl. grammatikai terminusok).
Reméljük, hogy az EFOP szótári munkálat és a hozzá kapcsolódó háttérkutatások elősegítik a siketek és nagyothallók társadalmi (például munkaerő-piaci) integrációját és életminőségük javulását, ezáltal hozzájárulnak a magyar gazdaság versenyképességének növeléséhez is.






A SINOSZ-szal közös identitás-projektumban létrejött a Siket Identitás Adatbázis. (Nyelvi szocializációs modellek és identitás a magyarországi siket közösségben (Identitás), FOG-FOF-10 (2010–2011)
További projektek:
- Anyanyelv, kétnyelvűség és iskola a Kárpát-medence kisebbségi régióiban, Illyés Közalapítvány (2004–2007)
- Kétnyelvűség és iskola a Muravidéken, MTA KI és a Lendvai Magyar Művelődési Intézet közös projektuma (2002–2006)
- Mercator Network of Language Diversity Centers tagja, régiós partner, EACEA LLP– EAC/30/07 (2009–2012) (Konzorciumvezető: Cor van der Meer, Fryske Akademy)
- Kárpát-medencei magyar nyelvi korpusz, NKFP 5/044/2002